
Haha geen probleem en goede vraag inderdaad!
Ik dacht dat ik had gezien in een youtubefilmpje dat iemand ging bekijken welke woorden samen werden gebruikt. Ik weet alleen even niet meer of hij dan ook
gesorteerd had op een kolom per woord of dat hij de hele tekst in één kolom had geplaatst. Dus er moet wel een manier zijn om ze in relatie met elkaar te bekijken, maar ik weet nog niet hoe haha dus dat moet ik nog even uitzoeken precies.
1 like
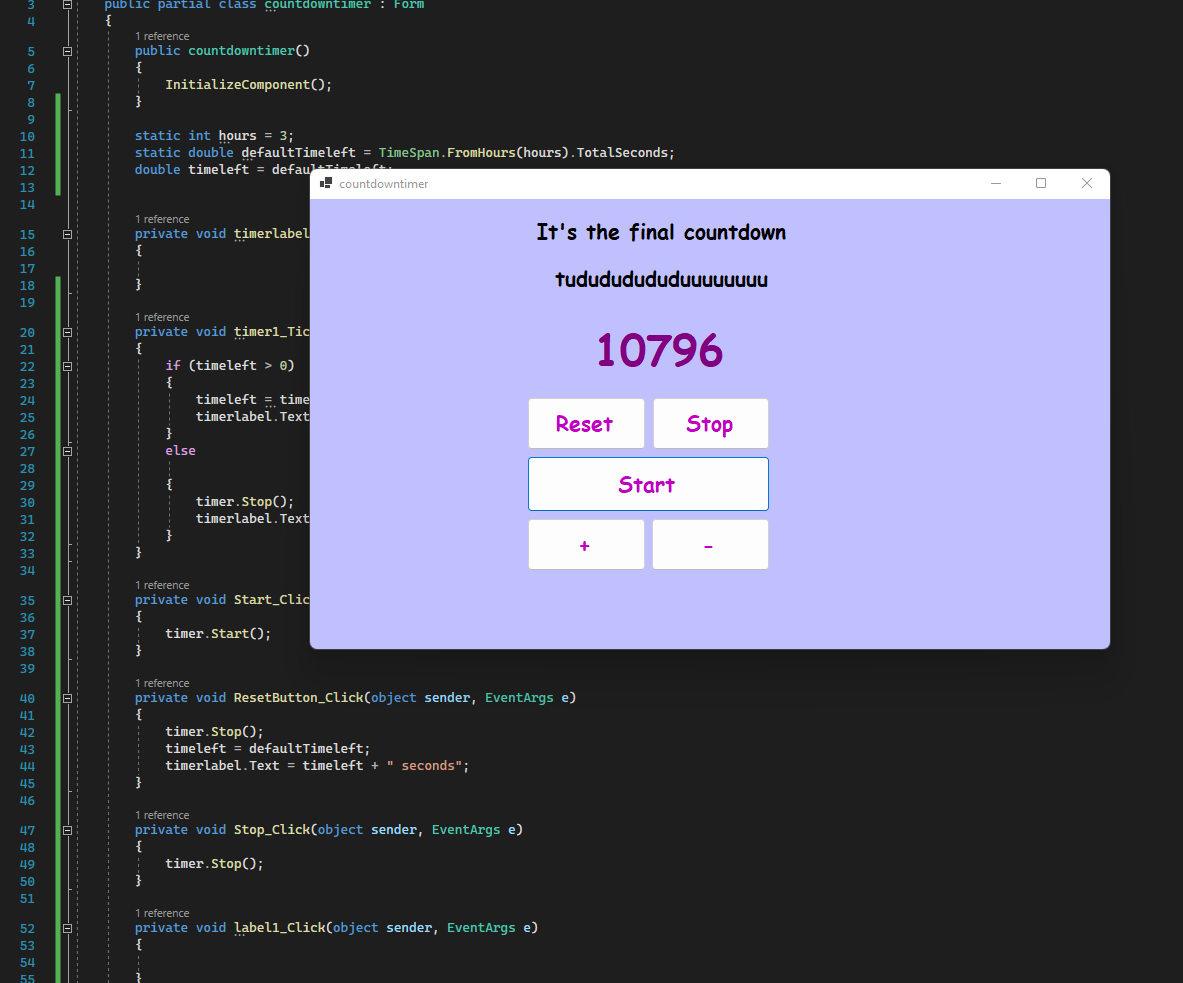
Bijna een jaar later ben ik eindelijk eens begonnen aan C#.
Weet niet of het legaal is dat mensen mij dit laten doen.
Enkel nog een glitterplaatje toevoegen en een warning wanneer de timer klaar is. en dan z’n vies popup ding alsof het psam lijkt uit het limewire tijdperk.
Dan vind ik mijn medicatie countdown wel geslaagd.
7 likes
Iemand ervaring met dataquest?
Ik wil vooral wat leren over SQL.